
前言
常有人在群里问或者直接问我:为啥我照着某个教程做了之后,路由器还是被查到了?学校检查我有没有用路由器的方法到底还有什么?我接下来应该怎么办?
应该说,很有可能的原因是,因为有些人喜欢用那种自带一吨插件的固件,觉得似乎插件多了更方便,结果却是把事情搞得一团糟,按照教程做的事情其实没有生效。所以我的建议还是:简单干净的固件,够用了,熟悉之后再折腾别的也不迟。
还有一个原因是我的锅,我的 xmurp-ua 插件虽然很多人用,但 master 分支并不能改掉所有 ua,dev 分支也还有 bug 没空修。但是我开源了,源代码就挂在那儿也没人帮我修,所以也不能完全算我的锅。
一般来说,如果真有人问我这个问题,我会说“不知道”,并建议去群里问问,因为我确实不知道他们学校啥情况。但群里的讨论也常常被带偏,比如大家都知道 MAC 地址很重要,于是就有人建议像统一 UA 或者 IPID 那样统一内网所有的 MAC 地址;又或者有人发现我的插件改不了 HTTPS 的 UA,于是觉得这是个重大的漏洞,在群里激起了热烈的讨论。总而言之:群里的人的知识水平还需要提高。
然而大家写教程,都只是写针对自己学校该怎么做,一些基础的概念却并不清楚。所以我想整这么一篇,作为做路由器反检测的一个通用的思路,而不是仅仅具体怎么做。另外也算是方便我自己:以后再有人问我这个问题,我可以直接把这篇文章甩给他,不用把重复的话再打一遍。另外本篇也只考虑反检测的事情,如何过认证,现在的方案已经很成熟了,也不是这件事的难点。
然而我自己的知识水平也是很有限的,我敢肯定这篇文章会有非常多的错误和不足,有问题就直说,大家一起来完善就好了。这本来也不是写给这个专业的学生看的,只是给像我一样的爱好者引个路。
本文章使用 CC 4.0 BY-SA 协议授权,啥意思呢,大概就是说:
- 要原文转载的话,不用联系我,但是要记得署名,包括我的大名(陈浩南)以及原链接。
- 如果基于我的内容再创作,新创作的内容必须同样是 CC 4.0 BY-SA 协议。
- 除此以外,随意发挥。
要是喜欢搞法律的话,可以看看这个法律意义上的申明。之所以使用 BY-SA 而不是 BY-NC-SA,是因为教程中使用的图片用的是 BY-SA。
本文仅仅发布在我自己的域名下(chn.moe)。如果你在什么论坛上发现相同的并且没注明出处,那不是我发的,那是他抄我。
我的联系方式在网站主页可以看到。也可以加我们的群(QQ 748317786),但是我很少看群。群里大多数都是小白,比较难的问题直接私聊管理员就可。
阅读指南
- 如果你是小白,并且不愿意了解更多细节,只想要个好用的 WiFi,那么去找你们学校的教程仔细地照着做就行,这篇文章不适合你。另外再提醒一句,尽可能用干净的固件,恩山之类的自带一吨插件的那种固件真的不适合你,出了问题在群里问也是没有人能回答的。
- 如果你是小白并且想要更深入地理解原理,那么“一些科普”这一部分应该是阅读的重点,这是一些必须的基础知识,有了这些才能继续前进。
- 如果你不是小白,那么建议跳过“一些科普”的部分直接看结论。如果可以发现有什么遗漏的地方并且指出来就更好了。
- 如果你是这个专业的,可以帮忙指出一些表述不准确的地方(我相信有很多)。
一些科普
这是一些基础的知识,侧重我们的目的(反路由器检测),并不是全面的资料。
五层协议
比如说:为了可以把这篇文章从我的服务器发送到你的电脑,互联网应该怎样设计?这其实是一个非常复杂的问题。
先来举一个别的例子。假如你掌管了全中国的快递,你需要保证绝大多数快递都可以被正确地送到,这也是一个非常复杂的问题。你应该怎样设计整个快递的系统,才能使得这个超级复杂的问题化解成一些比较容易解决的小问题?一个思路是:
- 雇一波人负责修车,保证汽车的零部件不会在半路上坏掉。这波人不用考虑具体开车时什么时候踩刹车什么时候踩油门,也不需要管这辆车将来会被派去送厦门的快递还是北京的快递,他们只需要保证车的质量就可以了,不需要考虑本职工作以外的内容。
- 再雇一波人负责开车。他们只需要在该踩刹车时踩刹车,改踩油门时踩油门;而不需要考虑车的发动机运转原理和修理方法,也不需要考虑南京到厦门的快递需要派几辆车过去,北京到天津的快递需要派几辆车过去。
- 再雇一拨人,负责计算南京到厦门的快递需要派几辆车过去,北京到天津的快递需要派几辆车过去;至于怎样修车、怎样开车,他们完全不用管。
我不知道真实的快递系统是不是这样运转的(应该不是),但真实的计算机网络确实是这样运转的:每一层协议只需要做好自己的本职工作,上层协议可以将下层协议实现的功能直接拿来用而不需要考虑它是怎样做到的。大致可以分成五层:
- 物理层:比如说,把
0101000110101一串需要传送的二进制内容翻译成网线上电压的波动或者空气中电磁场的波动,这就是物理层协议干的活。 - 链路层:比如说,几台电脑用网线直接连在一起,或者它们加入了同一个 WiFi。A 要给 B 发消息,但其实他发出的消息 C 也肯定能收到。如何让电脑们知道这个消息是谁发给谁的?这就是链路层干的活。链路层协议不需要再考虑“如果我要发
0100101,网线上的电压该如何波动”,因为这是物理层协议的活。 - 网络层:世界上的电脑并不是靠几根网线直接全都连在一起的。比如,你的手机要给我的服务器发一条消息,需要先发给宿舍的路由器,并要求路由器代为转发;然后路由器再转发给另一个路由器(可能是掌管整个小区网络的那个路由器),再转发给另一个路由器(可能是掌管整个城市网络的那个路由器),再经过好多好多次转发,才能到达我的服务器。而如果是同一个 WIFi 里手机给电脑发消息,就不需要惊动小区的路由器了,你俩直接聊就可以。这些是网络层协议要干的事情。
- 运输层:网络层的包在发生过程中是可能被搞丢的,因此有时需要对方收到数据后吱一声表示自己收到了;实际要发送的数据可能非常大,需要把它们拆成小包逐个发送,接收端全部接收到后再重新组合起来;数据在运输过程中可能会出错,收到后还需要校验一下,等等。这些通常是运输层协议要干的事情。
- 应用层:顾名思义,就是你打视频电话或者刷网页或者打原神时用到的那个协议。比方说,你看这个网页用到的是“超文本传输协议”,这个协议的一个功能是:你刷新一下这个页面,实际上这篇文章通常并不会真的再传输一遍,因为你的电脑上还有缓存,并且你的电脑与服务器按照“超文本传输协议”协商后发现,这段时间内网页并没有改变,所以就没有必要浪费这个流量再传输一遍,直接显示之前缓存的那个就好了。这就是应用层干的事情。
举个具体的例子。这篇文章从服务器传送到你的电脑,大致经历了下面的过程:
- 应用层:把这篇文章的内容压缩,然后在前面加上 HTTP 协议头(里面包含文章的长度、语言、编码、如何解压缩等信息),交给下层协议。当然,在此之前,他已经和你的电脑商量好了,确认你想看这篇文章而不是这个网站的别的文章。
- 运输层:把上面给的一大包内容加密后,前面加上关于如何解密的提示(TLS 协议);再切割成小段,在每一段前加上序号、校验和等信息,然后逐个交给下层协议,并等待对方的回复(TCP 协议)。当然,在这之前,它已经和你的电脑进行了协商,确认了你的电脑已经准备好接受数据(TCP),并且准备好解密数据(TLS)。
- 网络层:把上面给的东西前面加上源地址、目标地址等内容(IP 协议),然后交给下层协议。途中每一个路由器都会读取 IP 头,以确定下一步改把这个数据包交给谁。
- 链路层:装上链路层头和尾,发出去。途中每一个路由器收到信号后,都会根据链路层头来确认这是自己该收的数据,然后将收到的数据中的链路层头尾丢弃,新制作一个链路层头尾加上去,然后交给下层协议。
- 物理层:负责把把电压(或者电磁波)的波动翻译成
100101010,或者把100101010翻译成电压(或者电磁波)的波动。
“五层协议”不代表实际情况中,发送的数据都一定恰好套了五层协议;比如在上面的例子中,实际上套了至少六层(运输层协议有两层)。具体到哪个协议属于哪一层,每个人的理解在细节上也会不同,这不重要;划分为五层也并不是绝对的,只是方便理解而已,最正统的标准其实有七层,但通常理解成五层就够了,不需要自己给自己找麻烦。
最常用的协议
接下来是几个最常用到的协议。只是简单提一下,具体的资料网上有很多,不需要在这里重复。不介绍物理层的协议,因为我也不懂,而且和这篇文章的主题没有半毛钱关系。
链路层
Ethernet
就是所谓的“以太网”协议,和物理上的“以太”没有关系。这是一个链路层协议,几乎总在使用。平时说的形如 12:34:56:78:90:AB 的“MAC 地址”就是指这一层的地址,用来在一根网线上标记不同的计算机。
以下是一个以太网协议的数据包(术语叫“帧”)的结构。可以看到有源 MAC 地址和目标 MAC 地址的字段,Payload 就是实际传送的数据。可以认为,网线上五花八门的内容,最终都是装成这样的格式来传送的。

(图片版权:Public Domain,原地址)
PPPoE(PPP over Ethernet)
其实就是平时说的“拨号”或者“宽带连接”,是一个在以太网协议之上的链路层协议,也比较常用,但不是总在使用。
网络层
IP(Internet Protocol)
这是一个网络层的协议,几乎总在用,平时说的“IP 地址”就是指这一层的地址。原则上讲,连接到互联网的每一台计算机都应该有唯一的 IP 地址,虽然实际上并不是这样的,但基本上可以按照这个思路理解。现在大家都在用的 IP 协议是它的第四个版本,也就是 IPv4,IPv6 正在逐步推广。至于IPv5 的话,可能被制定标准的人吃掉了吧。

上图是一个 IPv4 数据报的结构。(图片版权:Michel Bakni, CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0, via Wikimedia Commons)
一些字段可以顾名思义,比如“Version”就是版本,在这里当然就是 4。“Source address”就是源 IP 地址,“Destination address”就是目标 IP 地址。“Data”就是它实际上要运送的数据。下面是关于 IP 头中几个其它需要用到的字段的说明。
ID(Identification)
这就是平时说的 IPID。理论上讲,如果上层协议给的一个数据包太大,IPv4 会将大数据包拆成小数据包(大约 1.5 kB)来发,下一个路由器收到所有的小数据包后,再组合成一个大数据包来处理。但实际情况下,为了效率,一般会尽量避免这种情况出现;我在自己的路由器上的测试,从来没有抓到过被分片的数据包。大多操作系统会连续递增地填充这个字段。IPv6 已经把 ID 字段砍掉了。
TTL(Time To Live)
这就是平时说的 TTL。一般初始时可能是 64 或者 128 等数值,每被路由器转发一次就减一,减到零之后就会被丢弃。因为一般情况下一个数据包不会经过 64 个路由器还没到目的地,如果发生这种情况就可以认为是路由配置错误,数据包在几个路由器之间被循环转发了。
ICMP(Internet Control Message Protocol)
一个网络层协议,基于 IP 协议,专门用来检查网络故障,通常说的“ping”就是这个协议的一个功能。
IPsec(Internet Protocol Security)
一个基于 IP 的加密协议,用得不多,目前只有一些 VPN 会用到。
运输层
TCP(Transmission Control Protocol)
两个几乎总在用的传输层协议之一,用来建立一个可以可靠地传输数据的“管道”。基本思路就是,要求接收端收到数据并且校验无误后吱一声,如果半天没有反应就认为数据丢了或者出错了,就再发一遍。
TCP 协议不区分服务端和客户端,通信中的双方是“平等”的,这与 HTTP 等上层协议不同。当然,对于单个 TCP 包,显然是需要区分源和目标的。

上图是一个 TCP 包的结构。(图片版权:Ere at Norwegian Wikipedia, Public domain, via Wikimedia Commons)
下面是关于 TCP 协议中几个概念的说明。在连接建立和断开的阶段,有一个“三次握手四次分手”的概念,有兴趣可以了解一下,这篇文章用不到所以不提。
端口
TCP 协议头中有源端口“Source Port”和目标端口“Destination port”,这样一个 IP 地址可以和另外一个 IP 地址建立很多个连接而不会混乱:只要一个 TCP 流中,两个 IP 地址加两个 TCP 端口,这四个东西中有一个不同,就认为它们不同。
对于特定的上层协议,习惯上会使用特定的服务端端口。例如,对于 HTTP 协议是 80 端口,HTTPS 协议是 443 端口。但这只是习惯,有很多打破习惯的情况,并不会引起什么问题。
滑动窗口
如果 TCP 协议设计成接收端每收到一个数据包都发送一个确认报文,发送端等到这个包确认收到之后再发下一个包,这个效率就太低了。实际的方法是协商一个大小合适的滑动窗口:一方面,接收端可以在接收到很多个数据包后只回复一次,例如“我已收到第 1365 至第 29840 字节的内容并确认无误”;另一方面,发送端也可以一口气多发几个数据包,只要已经发出但还没收到回复的内容的总长度比协商出的窗口小就可以了。
设计 TCP 协议时的网络远没有现在这样快,当时只在 TCP 头部留了两个字节用来表示窗口大小(窗口大小即 Window Size,两个字节也就意味着最多只允许有 65 kB 的数据同时等待确认)。后来当然不够用,就又加了一个 TCP 选项“window scale”,用来将窗口扩大到 2^n^ 倍。窗口的大小会根据实际情况动态调整,在传输数据的过程中也是可以调整的,但 window scale 只可以在建立连接的时候设置,并且不同操作系统设置的值不同。
UDP(User Datagram Protocol)
另一个几乎总在用的传输层协议,用来建立一个不可靠地传输数据的“管道”。比如说,打视频电话时,传输过程中数据有个别的丢失和错误也没关系,没有必要为了保证数据不出错而来回确认,这时常用 UDP 协议。UDP 协议同样有端口的概念,用法和 TCP 类似。至于这个协议为什么叫“User Datagram Protocol”,我也不知道。
TLS(Transport Layer Security)
一个在传输层加密的协议,常见的 HTTPS 其实就是 HTTP over TLS。这是一个非常廉价又非常坚固的加密:廉价到任何一个小破站都可以用(包括这里),坚固到即使动用国家力量也难以破解。当然,如果用的是太旧版本的 TLS(已经被证明不安全的加密方式),或者别人拿到了你的私钥,还是可以破解的。但就现实的问题来说,可以认为,第三方不可能查到内层数据除了长度以外的什么特征。
SNI(Server Name Indication)扩展
以 HTTPS 为例,为了在 TLS 协商的过程中就知道你访问的网站域名而不仅仅是 IP 地址(因为不同的域名可以用不同的证书来加密),就给 TLS 增加了这样一个扩展。SNI 的域名是明文传输的(因为这时还没有完成 TLS 的握手,没法加密),结果导致你访问的网站的域名是可以被第三方看到的。有修补的方法(ESNI),但还没有大规模应用。
应用层
HTTP(HyperText Transfer Protocol)
“HyperText”就是“超文本”。啥叫“超文本”呢,我也不知道,反正,绝大多数网页都是这个协议,很多不是网页的东西也用这个协议。通常基于 TCP,使用 80 端口;或基于 TCP+TLS(叫做 HTTPS),使用 443 端口;但最新的版本(HTTP/3)是基于 TLS+UDP 的,已经有一些应用。
HTTP 区分客户端和服务端,基本思路是“一问一答”,客户端向服务端发一个请求,服务端回复一个响应。下面是一个 HTTP 请求和它对应的响应的示例。(图片版权:CC-BY-SA 2.5,原地址。按照要求还应该标出作者,但是我找不到作者是谁。)
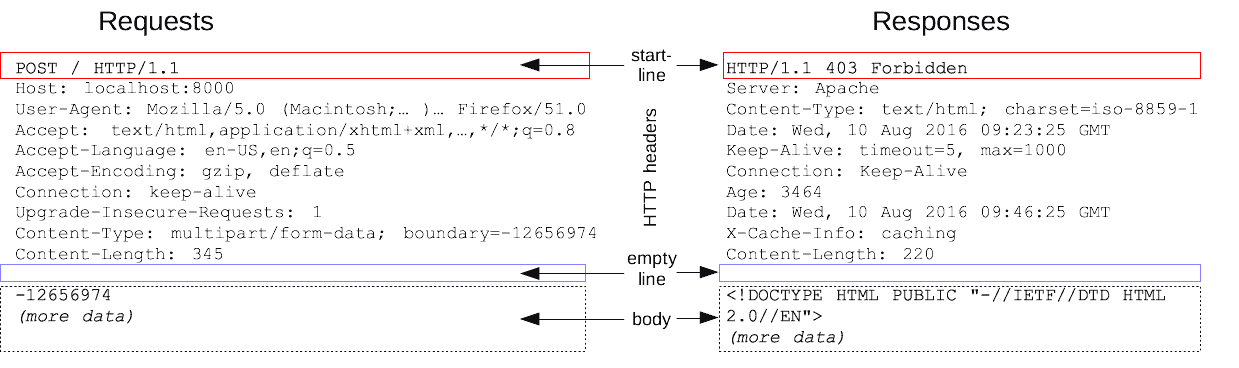
图中有提到 User-Agent,这就是平时说的 UA,它包含操作系统等信息。
HTTP 头中可以有的字段绝对不止图上这几个,而是非常非常多。
DNS(Domain Name System)
原则上,互联网上每一台电脑都有一个 IP 地址;但是这个地址不是给人记的,于是就给它起了个名字,比如说,“216.24.178.192”的名字叫“catalog.chn.moe”,这样就很好记了。把名字和 IP 地址对应起来的系统就叫 DNS。比方说,在浏览器地址栏敲“catalog.chn.moe”后,你的电脑会先问 DNS 服务器“catalog.chn.moe”对应的 IP 地址是什么,得到答复“216.24.178.192”后再开始与这个 IP 建立连接。用域名代替 IP 还有别的好处,这里不谈。
DNS 通常使用 UDP 53 端口,也有使用 TCP 53 端口的。也有 DoT(DNS over TLS)和 DoH(DNS over HTTPS),但用得比较少。
NTP(Network Time Protocol)
就是用来同步时间的那个协议。同步时间的意义不只是给你看表而已,比方说,TCP 头中就有一个字段用来放时间,接收端推断分片的顺序时会用到;再比方说,Vmess 也需要用时间来加密。
一般用 UDP 123 端口。
DHCP(Dynamic Host Configuration Protocol)
原先,每个电脑的 IP 地址都是手动配置的,不方便,这个协议就是用来自动配置 IP 地址的,顺便也会配置其它的内容(默认网关,默认 DNS 服务器)。服务端使用 UDP 67 端口,客户端使用 UDP 68 端口。
对于 IPv6,除了由 DHCP 服务器分配,也可以根据 MAC 地址自动生成一个 IP 地址。
网络地址转换(NAT)
如果你在大学上过一点点网络的课程,或者看过一点点他们的教科书,就会发现书本上的路由器与生活中所说的路由器是有区别的。区别在于,书本上的路由器一般指的是城市里、小区里的路由器,它们的工作只是转发,除了 IP 的 TTL 以及相应的校验和以外,网络层和网络层以上的内容不会发生任何变化;但家庭用的路由器至少还需要做网络地址转换。这对于折腾路由器是非常重要的,务必完全理解。
因为你只办了一个宽带的套餐,所以运营商只会给你一个 IP(比如说,120.36.242.54),但实际上需要你的手机、电脑、路由器本身都能上网。如果直接给三个设备都分配相同的 IP,那么当路由器收到一个 IP 数据包后,就不知道这个数据包是发给自己的,还是给电脑或者手机的。
所以实际情况下,是这样做的(以下 IP 地址和端口都只是举例,没有特殊意义):
- 运营商分配了一个 IP(120.36.242.54),路由器自己拿着。
- 路由器再开一个网卡,设定 IP 为 192.168.1.1,同时在这个网卡上启动 DHCP 服务端。
- 你的电脑与路由器的 192.168.1.1 的网卡连接到了同一个网络,路由器给他分配了一个 IP(192.168.1.100),同时申明默认网关为 192.168.1.1,子网掩码为 255.255.255.0。子网掩码 255.255.255.0 的意思是:如果目标 IP 地址与源 IP 地址(192.168.1.100)的前 24 个二进制位相同,说明这个 IP 地址就在这个网络内,可以直接通信;否则,发送给默认网关(192.168.1.1),由默认网关代为转发。
- 手机也连进来了,同样给他分配了一个 IP(192.168.1.101),告诉了他子网掩码和默认网关。
- 这时,你要用电脑看我的博客。在路由器看来,就是在 192.168.1.1 那张网卡上收到了一个内容为请求建立连接的 TCP/IP 数据包,源 IP 是 192.168.1.100、目标 IP 是 216.24.178.192、源端口是 6167、目标端口是 443。
- 路由不会直接 TTL 减一后转发,而是将源 IP 替换为 120.36.242.54,源端口 替换为 9634,TTL 减一后再发出;同时,在小本本上记下:地址 120.36.242.54、端口 9634 对应地址 192.168.1.100、端口 6167。
- 不一会儿,路由器收到了我的服务器的回复,源 IP 为 216.24.178.192、源端口为 443、目标 IP 为 216.24.178.192、目标端口为 9634。路由器对照着小本本,把目标 IP 改成了 192.168.1.100,目标端口改成了 6167,同时 TTL 减一,发出了。
- 又过了一会儿,收到了来自电脑的第二个包,源 IP 是 192.168.1.100、目标 IP 是 216.24.178.192、源端口是 6167、目标端口是 443。查小本本后,把源 IP 替换为 120.36.242.54,源端口 替换为 9634,TTL 减一后发出。
- 这样“左右逢源”一段时间后,路由器收到了断开连接前的最后一个包;又或者,已经很长时间没有数据包需要这样转换了,说明这个连接已经用不到了。这时,它会把“地址 120.36.242.54、端口 9634 对应地址 192.168.1.100、端口 6167”这一条在小本本上划掉。
大概就这样子。这样就实现了三个设备用一个 IP 上网的效果。
还有一个问题:按照上面这种情况,假如互联网上有另外一台电脑的 IP 是 192.168.1.111,那电脑和手机就无法连接到这台电脑了。因此,标准中专门规定 192.168.0.0/16、172.16.0.0/12、10.0.0.0/8 这三个范围的 IP 只用在内网。
抓包分析
如果在折腾路由器的过程中遇到了什么问题,或者想要实际看看网线上到底传了些啥,最简单粗暴有效的方法就是抓包,就是把传输过的内容原封不动地抓取下来。电脑上推荐使用 wireshark,路由器上推荐使用 tcpdump,抓好后再拿到电脑上分析。这里就不详细介绍用法了,网上的教程一抓一大把的。
所以,学校到底为啥能知道我用了路由器呢?
接下来来逐层分析,目标是找出所有可能暴露的地方。肯定有疏漏之处,所以需要随后再逐渐补充。
链路层
首先应该再次明确的是:经过路由器后,所有链路层的内容都被丢掉了,不要再在群里提“统一 MAC”之类的事情了。
Ethernet 中的 MAC
一方面,由 MAC 地址可以追踪到制造厂商,可能会发现这是路由器上的网卡型号;另一方面,有的学校可能会绑定账号和 MAC,换个设备就不能上网。改 MAC 也很简单,随便哪个路由器都支持。
网络层
IP ID
大多数操作系统会将 IP 头的 ID 设置为递增,而 NAT 时不会修改 ID。以时间为横坐标、ID 为纵坐标描点,没有使用路由器时应该是近似一条直线,使用后则会是多条直线(取决于 NAT 之后到底有几台设备)。这个方法在这篇论文中有描述。
解决方法也很简单,在内核中挂一个 netfilter 钩子去按需修改就可以了。我有写 rkp-ipid,可以直接拿去用。
IP TTL
不同操作系统的默认 TTL 不同,而且过路由器后 TTL 减一变成不常见的数(例如 63 或者 127)。也有论文说这种方法,但是我不想挂了,因为太明显了。
iptables 有模块可以直接修改。
1 | iptables -t mangle -A POSTROUTING -j TTL --ttl-set xxx |
在 OpenWrt 上,需要先安装 kmod-iptables-ipopt(感谢 Zxilly 的补充)。
运输层
以下都是在没有启用 IPsec 的前提下讨论。
TCP 协议的 timestamp
TCP 有一个时间戳的扩展字段经常用到。因为不同的机器可能使用不同的 NTP 服务器,导致内网各台设备之间有固定的时间差。它也可以用来检测,原理类似于 IPID,论文放在这里。
OpenWrt 自带一个 NTP 服务端,可以方便地解决这个问题。启用之后,把所有的 NTP 请求劫持到本地就行了。
1 | iptables -t nat -N ntp_force_local |
TCP 协议的 window size/scale
不同操作系统的 window scale 不同,linux 可以直接改内核参数来改,windows 不知道。同样不挂论文,因为太明显了。解决方法的话,同样 netfilter 挂个钩子就可以解决,不难,但是我没有去做,因为目前没发现哪个学校利用这一点。
TLS 协议的 SNI 扩展
一些域名可能是移动设备才会用到的,例如手机检测系统更新时访问的域名可能就是这样。现在还没有任何证据表明有学校这样做。
应用层
以下仅在没有启用 TLS 的前提下讨论。
HTTP 协议的 User-Agent
这是最常见的检测手段了。这里明文写着你的操作系统,用来判断再简单不过。同样不放论文。
修改起来也很容易,用 nginx 或者 privoxy 都可,但前提是性能要不太差,但普通家用路由器的性能就是太差了。Zxilly 补充,还有个 Polipo 可以用,性能也还行;不知道有没有人试用下,来反馈一下。
总之,为了效率,我写了个内核模块 xmurp-ua 来做这件事,原理同样是在内核里挂一个 netfilter 钩子。我实际拿到的是链路层的帧,要修改应用层的内容,难度还是很大的。目前 master 分支的版本没有考虑乱序或者多核处理器的情况,总之是假定我可以按照顺序拿到帧,这样在应用层找到对应的地方修改,把 User-Agent 改成 XMURP/1.0 加很多个空格(因为要保持长度不变,下层的才好处理)。dev 分支考虑了多核路由器和乱序的情况,试图严格地跟踪应用层的内容;但是有 bug,并且还没有找到在哪里。即使将 bug 修好,这个插件也还有另外的严重问题:User-Agent 有太多空格。这个问题也还需要解决。这是目前除了普及已有成果以外最急需要做的事情,但是不知为何只有我一个人做。
对于 HTTPS,若在浏览器中设置了代理,在进行正式的加密通讯之前,会先发送一个不加密的 HTTP 请求(connect 方法)。详细内容可以阅读这一篇文章。这一点是由 Zxilly 补充的。
DNS 查询、HTTP 协议的 Host 字段
与 TLS 的 SNI 相同,不再重复。
HTTP JavaScript 注入
这是个非常邪恶的做法,但我觉得是他们最有可能下一步去做的。解决方法,只能具体情况再看,根据特征去屏蔽。
之所以觉得他们下一步会做,是因为这帮人并不会因为这是个邪恶的做法就不去做;相反,早有人用这样的方法插入广告,或者把你要下载的软件替换成 360 手机助手。这与强盗无异,是妥妥的犯罪,虽然总有人被逮,但就是有人要去做。
话说回来,现在拿 UA 查路由器的做法,也不见得合法,并没有任何法律允许他们这样做;相反,“除非我同意了,否则服务提供商不应该以‘我要发财’为理由收集我的个人信息”,这才是共识。
DHCP 协议的主机名
海韵 16 的交换机里,人头攒动。大家的名字都叫“Desktop-xxx”,这时忽然有个叫“OpenWrt”或者“HiWiFi”的家伙冒出来,不封你封谁呢?
OpenWrt 要改主机名很容易,但普通路由器未必可以。目前还没有证据证明有学校使用了这个方法,但改一下也很简单。
其它
这篇文章提到不同操作系统的 TCP SYN 数据包长度不一样,我觉得没道理,故没有列入。同一篇文章还提到用 TCP 的端口号来检测,但并没有说明怎么检测(有什么特征),因此我也没有列入;但如果说通常的 NAT 程序在这里确实会造成什么特征的话,也是有可能的。
这篇文章提到了 IP 协议的 DF 字段有一定特征。我抓包发现,自己电脑(Linux)网卡上的包 DF 几乎全是 1;在路由器的 br-lan 上抓包,DF 大约一半是 1 一半是 0。这可能是一个特征,但还需要进一步确认,暂时不列入。
这篇文章很有趣。他提到了与流量大小相关的一些特征,例如一段时间内 DNS 查询数,TCP SYN 包数等——说白了就是,接入的设备多,流量就大。这些数据不容易直接使用,于是就套了一个支持向量机的方法来;当 NAT 后面设备数不小于 5 的时候,实验室中准确率接近百分之百。
如果这个方法在实际情况下确认可用,那么就是死棋,无法绕过;但是真的可用吗?其一,每个人的上网习惯不同本身就导致流量的巨大差异,这在实验中未必能体现出来;其二,这篇文章发表于十年前,现在 TCP 长连接已经很常见了,关于 TCP 的流量特征肯定有很大改变,未必还能用。
PS:上两段中提到的文章来自北邮,但是实际上没有听说北邮有禁止路由器使用的情况。
更新记录
- 40734:完成正文。